CVPR 2026
M3Grounder:
Mask-Based Multi-Span and Multi-Granular
Grounding for Document QA
Venkat Kesav Venna1,*,
Sai Madhusudan Gunda2,*,
Jyothi Swaroopa Jinka2,†,
Hrithik Sagar Rachakonda2,†,
Anirudh Srinivasan1,
Ravi Kiran Sarvadevabhatla1,2
1 BharatGen 2 IIIT Hyderabad
* Equal contribution † Equal contribution

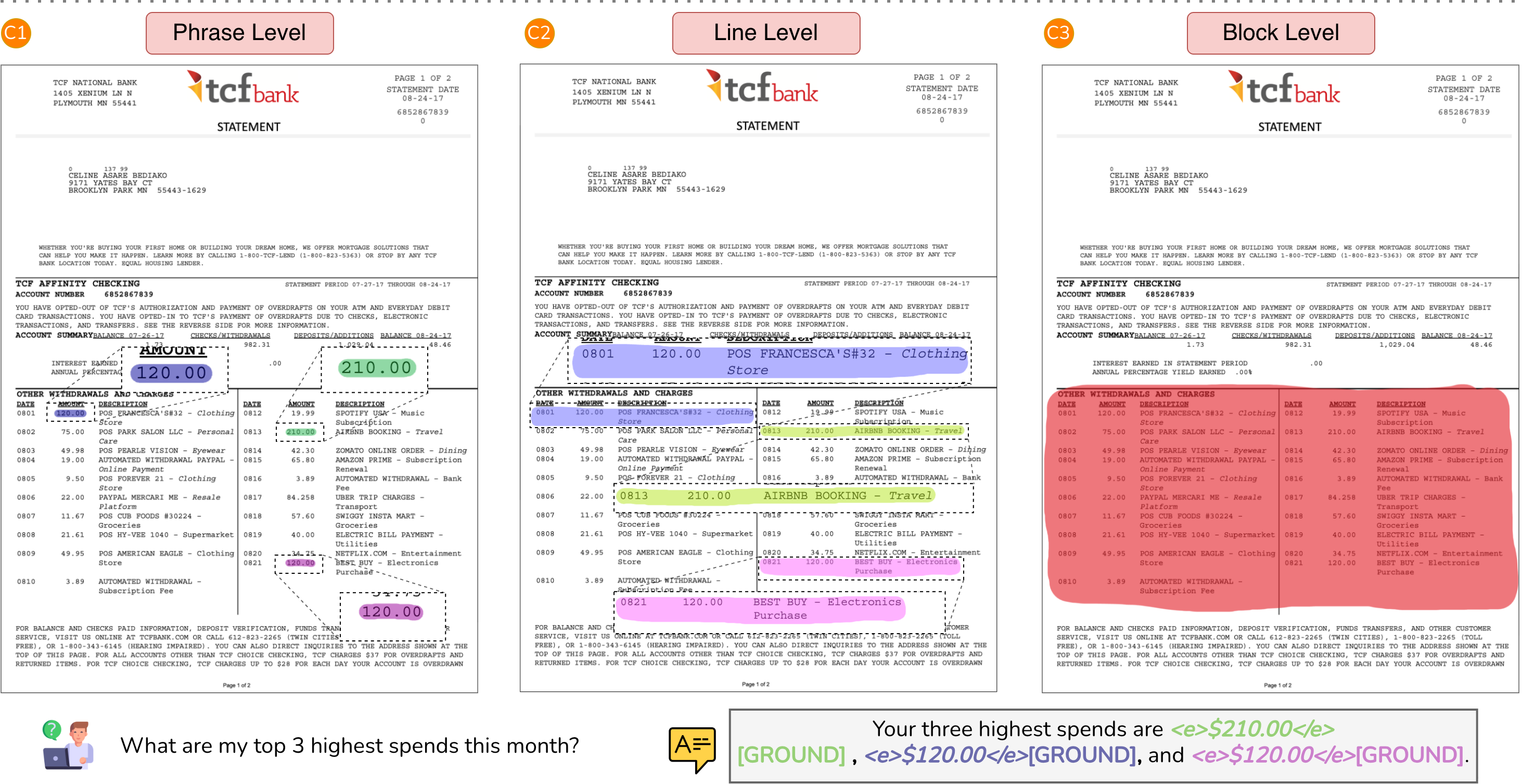
M3Grounder in action:
Each example shows a QA pair. The predicted answer text contains interleaved
[GROUND]
tokens which map answer spans to corresponding grounding regions.
A,
B
demonstrate precise segmentation without spillover into irrelevant regions.
B
shows effective grounding for dense, multi-span evidence in complex document layouts.
C1,
C2,
C3
illustrate multi-granular grounding, where the grounding scope expands hierarchically
(phrase \( \subset \) line \( \subset \) block).